

Bonjour à tous !
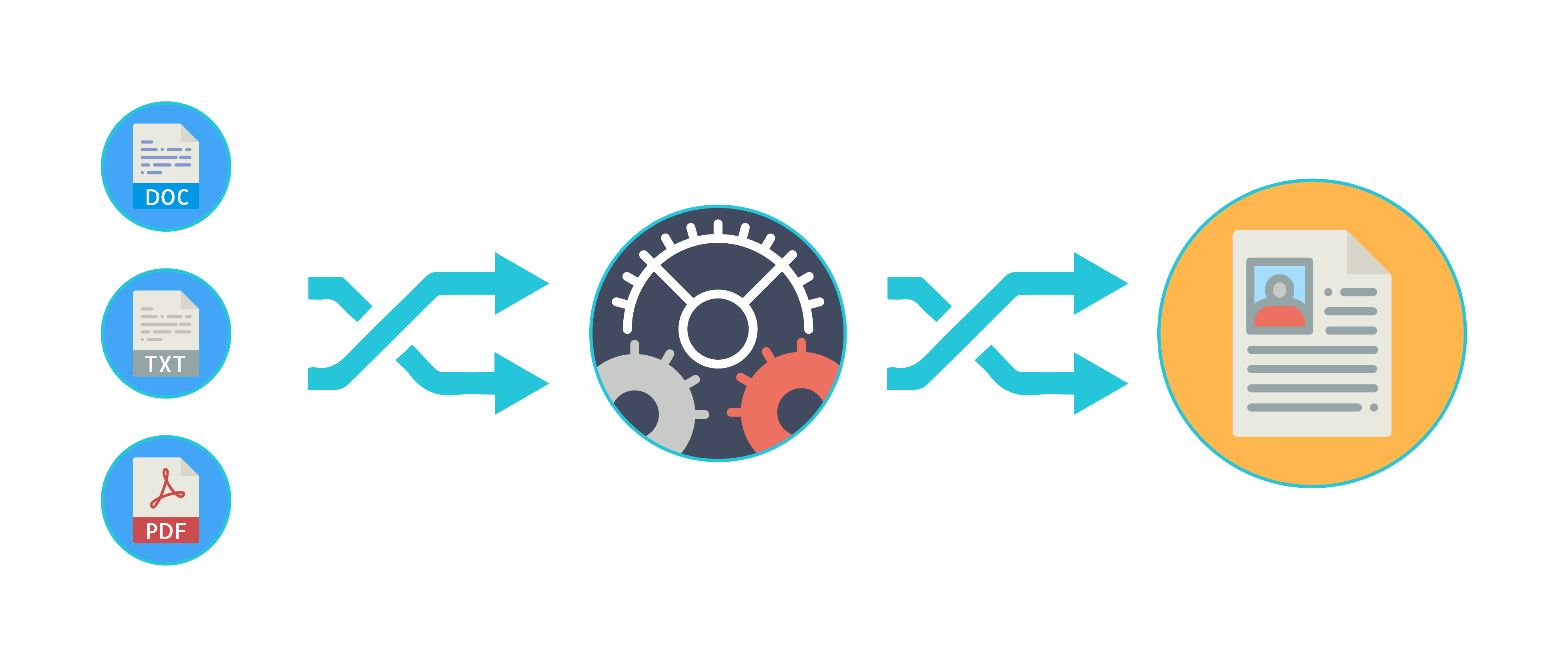
À l'intersection entre l'OCR, le NLP et la Computer Vision : le parsing de CV. En entrée : un pdf ou une image, en sortie un JSON contenant toutes les infos du CV.
L'une des problématiques prédominantes en Ressources Humaines est la lecture de CVs. L'une des étapes clés du recrutement consiste à filtrer les CVs, en ciblant les informations les plus importantes contenues dans ces derniers : l'éducation, l'expérience, le permis de conduire, l'âge, le lieu de vie, etc…. Cette tâche chronophage bénéficie depuis plusieurs années de l'aide de l'IA pour gagner en rapidité.
Nous avons intervenu auprès de plusieurs entreprises RH pour intégrer des outils d'IA permettant d'automatiser cette phase d'extraction d'informations. Plusieurs modules de Machine Learning interviennent dans ce type d'outil.
L'OCR, ou Optical Character Recognition, permet de convertir les images contenant du texte, en texte. C'est un des cas d'usage les plus vieux du Machine Learning. Le NLP, ou Natural Language Processing, permet quant à lui de classifier les informations reconnues, permettant ainsi de séparer Nom/Prénom de l'université par exemple. Plus précisément, il s'agit ici d'un domaine spécifique du NLP : la Named Entity Recognition (NER).
Enfin, lorsque l'on cherche également à extraire la photo de profil des candidats, on fait appel à un autre domaine bien connu du Machine Learning, la Computer Vision. Ainsi on identifie la partie du CV contenant un visage, et on l'extrait.
Pour résumer, dans ce type de contrats, nous avons participé à la conversion de CVs au format PDF en informations classifiées sous un JSON propre. Si vous souhaitez en discuter plus avant, n'hésitez pas à prendre rendez-vous ici
À bientôt !